![]()
Oct-2023 Get Totally Free Updates on Professional-Machine-Learning-Engineer Dumps PDF Questions
Prepare With Top Rated High-quality Professional-Machine-Learning-Engineer Dumps For Success in Professional-Machine-Learning-Engineer Exam
The Google Professional-Machine-Learning-Engineer exam covers a range of topics, including data preparation and feature engineering, model training, optimization, and deployment. Candidates must demonstrate their ability to use machine learning tools and technologies to create scalable, efficient, and accurate models. Professional-Machine-Learning-Engineer exam also tests their knowledge of best practices for machine learning, data processing, and model evaluation.
Google Professional Machine Learning Engineer certification is highly respected in the industry and is recognized as a benchmark for excellence in machine learning. Achieving this certification demonstrates to employers and peers that a candidate has the skills and knowledge required to design, build, and deploy machine learning models on Google Cloud Platform. Google Professional Machine Learning Engineer certification is ideal for data scientists, machine learning engineers, software engineers, and other professionals who are looking to enhance their skills in machine learning and advance their career in this field.
NEW QUESTION # 31
You want to rebuild your ML pipeline for structured data on Google Cloud. You are using PySpark to conduct data transformations at scale, but your pipelines are taking over 12 hours to run. To speed up development and pipeline run time, you want to use a serverless tool and SQL syntax. You have already moved your raw data into Cloud Storage. How should you build the pipeline on Google Cloud while meeting the speed and processing requirements?
- A. Ingest your data into Cloud SQL convert your PySpark commands into SQL queries to transform the data, and then use federated queries from BigQuery for machine learning
- B. Use Data Fusion's GUI to build the transformation pipelines, and then write the data into BigQuery
- C. Convert your PySpark into SparkSQL queries to transform the data and then run your pipeline on Dataproc to write the data into BigQuery.
- D. Ingest your data into BigQuery using BigQuery Load, convert your PySpark commands into BigQuery SQL queries to transform the data, and then write the transformations to a new table
Answer: C
NEW QUESTION # 32
You work at a subscription-based company. You have trained an ensemble of trees and neural networks to predict customer churn, which is the likelihood that customers will not renew their yearly subscription. The average prediction is a 15% churn rate, but for a particular customer the model predicts that they are 70% likely to churn. The customer has a product usage history of 30%, is located in New York City, and became a customer in 1997. You need to explain the difference between the actual prediction, a 70% churn rate, and the average prediction. You want to use Vertex Explainable AI. What should you do?
- A. Train local surrogate models to explain individual predictions.
- B. Configure integrated gradients explanations on Vertex Explainable AI.
- C. Configure sampled Shapley explanations on Vertex Explainable AI.
- D. Measure the effect of each feature as the weight of the feature multiplied by the feature value.
Answer: A
NEW QUESTION # 33
Your data science team is training a PyTorch model for image classification based on a pre-trained RestNet model. You need to perform hyperparameter tuning to optimize for several parameters. What should you do?
- A. Run a hyperparameter tuning job on AI Platform using custom containers.
- B. Create a Kuberflow Pipelines instance, and run a hyperparameter tuning job on Katib.
- C. Convert the model to a TensorFlow model, and run a hyperparameter tuning job on AI Platform.
- D. Convert the model to a Keras model, and run a Keras Tuner job.
Answer: B
NEW QUESTION # 34
Which of the following metrics should a Machine Learning Specialist generally use to compare/evaluate machine learning classification models against each other?
- A. Recall
- B. Area Under the ROC Curve (AUC)
- C. Misclassification rate
- D. Mean absolute percentage error (MAPE)
Answer: B
NEW QUESTION # 35
You work for a company that provides an anti-spam service that flags and hides spam posts on social media platforms. Your company currently uses a list of 200,000 keywords to identify suspected spam posts. If a post contains more than a few of these keywords, the post is identified as spam. You want to start using machine learning to flag spam posts for human review. What is the main advantage of implementing machine learning for this business case?
- A. Spam posts can be flagged using far fewer keywords.
- B. A much longer keyword list can be used to flag spam posts.
- C. New problematic phrases can be identified in spam posts.
- D. Posts can be compared to the keyword list much more quickly.
Answer: D
NEW QUESTION # 36
You work on a data science team at a bank and are creating an ML model to predict loan default risk. You have collected and cleaned hundreds of millions of records worth of training data in a BigQuery table, and you now want to develop and compare multiple models on this data using TensorFlow and Vertex AI. You want to minimize any bottlenecks during the data ingestion state while considering scalability. What should you do?
- A. Export data to CSV files in Cloud Storage, and use tf.data.TextLineDataset() to read them.
- B. Convert the data into TFRecords, and use tf.data.TFRecordDataset() to read them.
- C. Use TensorFlow I/O's BigQuery Reader to directly read the data.
- D. Use the BigQuery client library to load data into a dataframe, and use tf.data.Dataset.from_tensor_slices() to read it.
Answer: A
NEW QUESTION # 37
You have trained a model on a dataset that required computationally expensive preprocessing operations. You need to execute the same preprocessing at prediction time. You deployed the model on Al Platform for high-throughput online prediction. Which architecture should you use?
- A. * Send incoming prediction requests to a Pub/Sub topic
* Transform the incoming data using a Dataflow job
* Submit a prediction request to Al Platform using the transformed data
* Write the predictions to an outbound Pub/Sub queue - B. * Send incoming prediction requests to a Pub/Sub topic
* Set up a Cloud Function that is triggered when messages are published to the Pub/Sub topic.
* Implement your preprocessing logic in the Cloud Function
* Submit a prediction request to Al Platform using the transformed data
* Write the predictions to an outbound Pub/Sub queue - C. * Validate the accuracy of the model that you trained on preprocessed data
* Create a new model that uses the raw data and is available in real time
* Deploy the new model onto Al Platform for online prediction - D. * Stream incoming prediction request data into Cloud Spanner
* Create a view to abstract your preprocessing logic.
* Query the view every second for new records
* Submit a prediction request to Al Platform using the transformed data
* Write the predictions to an outbound Pub/Sub queue.
Answer: A
Explanation:
https://cloud.google.com/architecture/data-preprocessing-for-ml-with-tf-transform-pt1#where_to_do_preprocessing
NEW QUESTION # 38
A Machine Learning Specialist is designing a system for improving sales for a company. The objective is to use the large amount of information the company has on users' behavior and product preferences to predict which products users would like based on the users' similarity to other users.
What should the Specialist do to meet this objective?
- A. Build a model-based filtering recommendation engine with Apache Spark ML on Amazon EMR
- B. Build a combinative filtering recommendation engine with Apache Spark ML on Amazon EMR
- C. Build a collaborative filtering recommendation engine with Apache Spark ML on Amazon EMR.
- D. Build a content-based filtering recommendation engine with Apache Spark ML on Amazon EMR
Answer: C
Explanation:
Many developers want to implement the famous Amazon model that was used to power the "People who bought this also bought these items" feature on Amazon.com. This model is based on a method called Collaborative Filtering. It takes items such as movies, books, and products that were rated highly by a set of users and recommending them to other users who also gave them high ratings. This method works well in domains where explicit ratings or implicit user actions can be gathered and analyzed.
Reference: https://aws.amazon.com/blogs/big-data/building-a-recommendation-engine-with-spark-ml-on-amazon-emr-using-zeppelin/
NEW QUESTION # 39
You have trained a deep neural network model on Google Cloud. The model has low loss on the training data, but is performing worse on the validation dat a. You want the model to be resilient to overfitting. Which strategy should you use when retraining the model?
- A. Apply a dropout parameter of 0 2, and decrease the learning rate by a factor of 10
- B. Run a hyperparameter tuning job on Al Platform to optimize for the learning rate, and increase the number of neurons by a factor of 2.
- C. Apply a 12 regularization parameter of 0.4, and decrease the learning rate by a factor of 10.
- D. Run a hyperparameter tuning job on Al Platform to optimize for the L2 regularization and dropout parameters
Answer: B
NEW QUESTION # 40
You have trained a text classification model in TensorFlow using Al Platform. You want to use the trained model for batch predictions on text data stored in BigQuery while minimizing computational overhead. What should you do?
- A. Use Dataflow with the SavedModel to read the data from BigQuery
- B. Export the model to BigQuery ML.
- C. Submit a batch prediction job on Al Platform that points to the model location in Cloud Storage.
- D. Deploy and version the model on Al Platform.
Answer: B
Explanation:
https://cloud.google.com/bigquery-ml/docs/making-predictions-with-imported-tensorflow-models
https://cloud.google.com/bigquery-ml/docs/making-predictions-with-imported-tensorflow-models#importing_models
https://cloud.google.com/bigquery-ml/docs/making-predictions-with-imported-tensorflow-models#bq CREATE OR REPLACE MODEL example_dataset.imported_tf_model OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')
NEW QUESTION # 41
You are training an object detection model using a Cloud TPU v2. Training time is taking longer than expected. Based on this simplified trace obtained with a Cloud TPU profile, what action should you take to decrease training time in a cost-efficient way?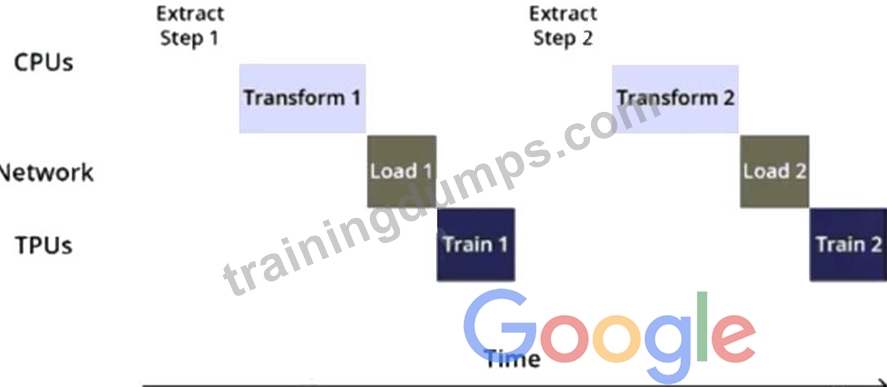
- A. Move from Cloud TPU v2 to 8 NVIDIA V100 GPUs and increase batch size.
- B. Rewrite your input function to resize and reshape the input images.
- C. Rewrite your input function using parallel reads, parallel processing, and prefetch.
- D. Move from Cloud TPU v2 to Cloud TPU v3 and increase batch size.
Answer: D
NEW QUESTION # 42
You work for an online travel agency that also sells advertising placements on its website to other companies.
You have been asked to predict the most relevant web banner that a user should see next. Security is important to your company. The model latency requirements are 300ms@p99, the inventory is thousands of web banners, and your exploratory analysis has shown that navigation context is a good predictor.
You want to Implement the simplest solution. How should you configure the prediction pipeline?
- A. Embed the client on the website, deploy the gateway on App Engine, deploy the database on Cloud Bigtable for writing and for reading the user's navigation context, and then deploy the model on AI Platform Prediction.
- B. Embed the client on the website, deploy the gateway on App Engine, deploy the database on Memorystore for writing and for reading the user's navigation context, and then deploy the model on Google Kubernetes Engine.
- C. Embed the client on the website, and then deploy the model on AI Platform Prediction.
- D. Embed the client on the website, deploy the gateway on App Engine, and then deploy the model on AI Platform Prediction.
Answer: D
NEW QUESTION # 43
You are developing an ML model that uses sliced frames from video feed and creates bounding boxes around specific objects. You want to automate the following steps in your training pipeline: ingestion and preprocessing of data in Cloud Storage, followed by training and hyperparameter tuning of the object model using Vertex AI jobs, and finally deploying the model to an endpoint. You want to orchestrate the entire pipeline with minimal cluster management. What approach should you use?
- A. Use Vertex AI Pipelines with Kubeflow Pipelines SDK.
- B. Use Kubeflow Pipelines on Google Kubernetes Engine.
- C. Use Cloud Composer for the orchestration.
- D. Use Vertex AI Pipelines with TensorFlow Extended (TFX) SDK.
Answer: B
NEW QUESTION # 44
You have trained a deep neural network model on Google Cloud. The model has low loss on the training data, but is performing worse on the validation dat a. You want the model to be resilient to overfitting. Which strategy should you use when retraining the model?
- A. Run a hyperparameter tuning job on Al Platform to optimize for the learning rate, and increase the number of neurons by a factor of 2.
- B. Apply a 12 regularization parameter of 0.4, and decrease the learning rate by a factor of 10.
- C. Run a hyperparameter tuning job on Al Platform to optimize for the L2 regularization and dropout parameters
- D. Apply a dropout parameter of 0 2, and decrease the learning rate by a factor of 10
Answer: D
NEW QUESTION # 45
You are training a Resnet model on Al Platform using TPUs to visually categorize types of defects in automobile engines. You capture the training profile using the Cloud TPU profiler plugin and observe that it is highly input-bound. You want to reduce the bottleneck and speed up your model training process. Which modifications should you make to the tf .data dataset?
Choose 2 answers
- A. Reduce the value of the repeat parameter
- B. Increase the buffer size for the shuffle option.
- C. Decrease the batch size argument in your transformation
- D. Use the interleave option for reading data
- E. Set the prefetch option equal to the training batch size
Answer: C,E
Explanation:
https://towardsdatascience.com/overcoming-data-preprocessing-bottlenecks-with-tensorflow-data-service-nvidia-dali-and-other-d6321917f851
NEW QUESTION # 46
A Machine Learning team uses Amazon SageMaker to train an Apache MXNet handwritten digit classifier model using a research dataset. The team wants to receive a notification when the model is overfitting.
Auditors want to view the Amazon SageMaker log activity report to ensure there are no unauthorized API calls.
What should the Machine Learning team do to address the requirements with the least amount of code and fewest steps?
- A. Implement an AWS Lambda function to log Amazon SageMaker API calls to Amazon S3. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
- B. Use AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Set up Amazon SNS to receive a notification when the model is overfitting
- C. Implement an AWS Lambda function to log Amazon SageMaker API calls to AWS CloudTrail. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
- D. Use AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
Answer: C
NEW QUESTION # 47
You are a lead ML engineer at a retail company. You want to track and manage ML metadata in a centralized way so that your team can have reproducible experiments by generating artifacts. Which management solution should you recommend to your team?
- A. Manage all relational entities in the Hive Metastore.
- B. Manage your ML workflows with Vertex ML Metadata.
- C. Store your tf.logging data in BigQuery.
- D. Store all ML metadata in Google Cloud's operations suite.
Answer: D
NEW QUESTION # 48
......
Get 100% Success with Latest Google Cloud Certified Professional-Machine-Learning-Engineer Exam Dumps: https://pdfvce.trainingdumps.com/Professional-Machine-Learning-Engineer-valid-vce-dumps.html